Choose mode
About MiniCPM-o 4.5
MiniCPM-o 4.5 is the latest and most capable model in the MiniCPM-o series. The model is built in an end-to-end fashion based on SigLip2, Whisper-medium, CosyVoice2, and Qwen3-8B with a total of 9B parameters. It exhibits a significant performance improvement, and introduces new features for full-duplex multimodal live streaming.
Leading Visual Capability
MiniCPM-o 4.5 achieves an average score of 77.6 on OpenCompass, a comprehensive evaluation of 8 popular benchmarks. With only 9B parameters, it surpasses widely used proprietary models like GPT-4o, Gemini 2.0 Pro, and approaches Gemini 2.5 Flash for vision-language capabilities.
Strong Speech Capability
MiniCPM-o 4.5 supports bilingual real-time speech conversation with configurable voices in English and Chinese. It features more natural, expressive and stable speech conversation. The model also allows for fun features such as voice cloning and role play via a simple reference audio clip.
Full-Duplex Multimodal Live Streaming
MiniCPM-o 4.5 can process real-time, continuous video and audio input streams simultaneously while generating concurrent text and speech output streams in an end-to-end fashion, without mutual blocking. This allows MiniCPM-o 4.5 to see, listen, and speak simultaneously.
Strong OCR Capability & Efficiency
MiniCPM-o 4.5 can process high-resolution images (up to 1.8 million pixels) and high-FPS videos (up to 10fps) in any aspect ratio efficiently. It achieves state-of-the-art performance for end-to-end English document parsing on OmniDocBench.
Easy Usage
MiniCPM-o 4.5 can be easily used in various ways: PyTorch inference with Nvidia GPU, llama.cpp and Ollama for efficient CPU inference on local devices, int4 and GGUF quantized models in 16 sizes, vLLM and SGLang for high-throughput inference, and more.
Model Architecture
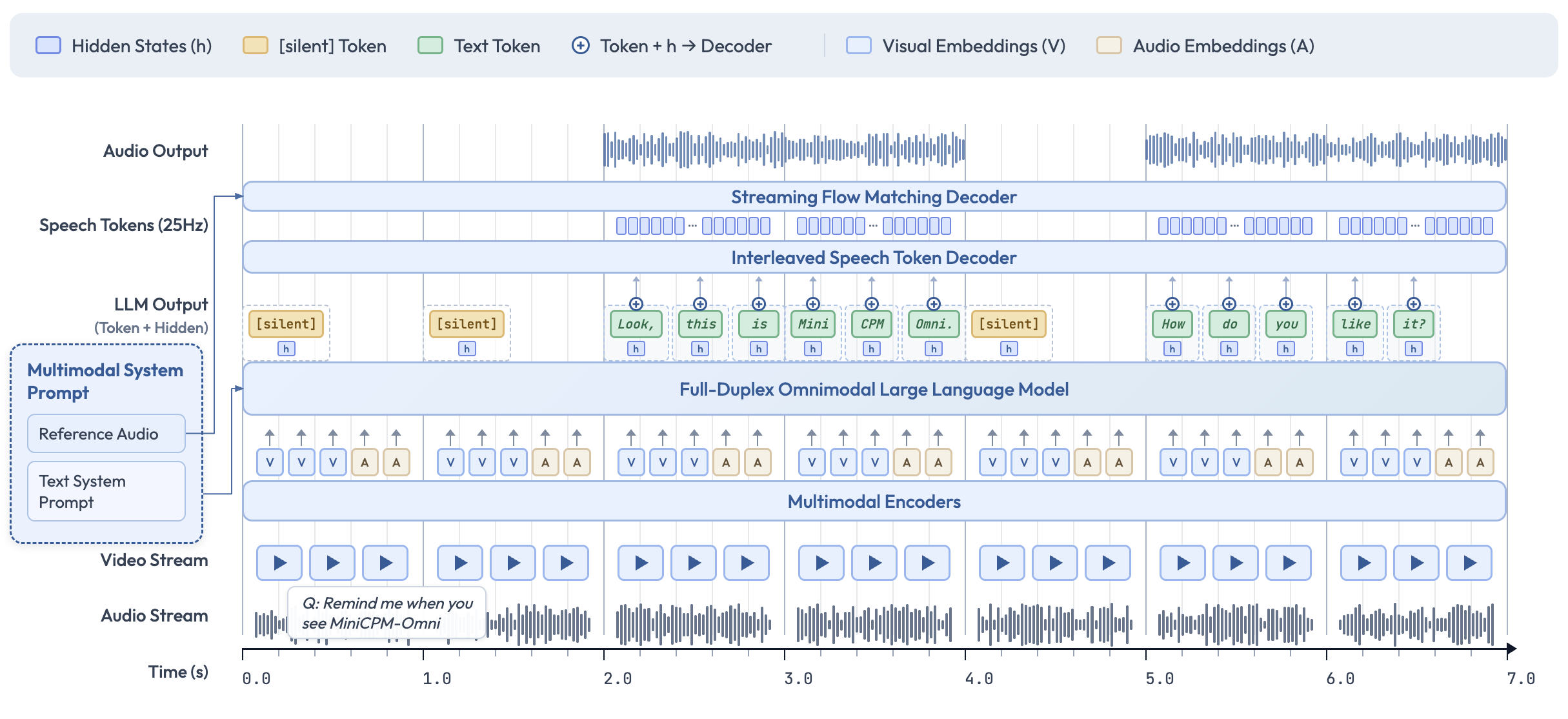
End-to-end Omni-modal Architecture
The modality encoders/decoders and LLM are densely connected via hidden states in an end-to-end fashion. This enables better information flow and control, and also facilitates full exploitation of rich multimodal knowledge during training.
Full-Duplex Omni-modal Live Streaming Mechanism
We turn the offline modality encoder/decoders into online and full-duplex ones for streaming inputs/outputs. The speech token decoder models text and speech tokens in an interleaved fashion to support full-duplex speech generation. We sync all the input and output streams on timeline in milliseconds via a time-division multiplexing (TDM) mechanism.
Proactive Interaction Mechanism
The LLM continuously monitors the input video and audio streams, and decides at a frequency of 1Hz to speak or not. This high decision-making frequency together with full-duplex nature are crucial to enable the proactive interaction capability.
Configurable Speech Modeling Design
We inherit the multimodal system prompt design of MiniCPM-o 2.6, which includes a traditional text system prompt, and a new audio system prompt to determine the assistant voice. This enables cloning new voices and role play in inference time for speech conversation.
Model Capability Comparison
| Model | Speech Duplex |
Omni Duplex |
Live Video Captioning |
Omni Q&A |
Proactive Reminders |
Half-Duplex Call |
Custom Voice |
Speech Synthesis |
OCR |
|---|---|---|---|---|---|---|---|---|---|
| Moshi | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Qwen3-Omni | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| StreamingVLM | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| LiveCC | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| GPT-4o | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Gemini 2.5 | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| MiniCPM-o 4.5 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |